Hints and Tips
This page provides some solutions for problems we’ve encountered ourselves or have been raised on the Apache Causeway mailing lists.
Tracing SQL Statements
If you want to debug the SQL being sent to the database, one approach is to use the p6spy JDBC Driver. This acts as a decorator, logging the calls and then passing through to the underlying database.
Enabling p6spy is easily done using the gavlyukovskiy/spring-boot-data-source-decorator package:
-
add the
com.github.gavlyukovskiy:p6spy-spring-boot-starterdependency to yourpom.xml:pom.xml<dependency> <groupId>com.github.gavlyukovskiy</groupId> <artifactId>p6spy-spring-boot-starter</artifactId> <version>1.7.1</version> <scope>compile</scope> (1) </dependency>1 change to testif only using within integration tests, for example. -
add properties to enable logging:
application.properties# Register P6LogFactory to log JDBC events decorator.datasource.p6spy.enable-logging=true # Use com.p6spy.engine.spy.appender.MultiLineFormat instead of com.p6spy.engine.spy.appender.SingleLineFormat decorator.datasource.p6spy.multiline=true # Use logging for default listeners [slf4j, sysout, file, custom] decorator.datasource.p6spy.logging=sysout ## Log file to use (only with logging=file) #decorator.datasource.p6spy.log-file=spy.log ## Class file to use (only with logging=custom). The class must implement com.p6spy.engine.spy.appender.FormattedLogger #decorator.datasource.p6spy.custom-appender-class=my.custom.LoggerClass ## Custom log format, if specified com.p6spy.engine.spy.appender.CustomLineFormat will be used with this log format #decorator.datasource.p6spy.log-format= ## Use regex pattern to filter log messages. If specified only matched messages will be logged. #decorator.datasource.p6spy.log-filter.pattern= ## Report the effective sql string (with '?' replaced with real values) to tracing systems. ## NOTE this setting does not affect the logging message. #decorator.datasource.p6spy.tracing.include-parameter-values=true
The integration makes it easy to set the most common configuration properties, but it’s also possible to configure other p6spy properties using its various configuration mechanisms; see p6spy docs for details.
Rather than adding the properties directly to application.properties, you might prefer to set up a "p6spy" profile so that the configuration can be enabled/disabled easily:
-
create a properties file for a "p6spy" profile, in either the root or
configpackage:application-p6spy.properties... -
move the configuration properties from
application.propertiesintoapplication-p6spy.properties -
enable the
p6spyprofile using thespring.profiles.activesystem property:-Dspring.profiles.active=p6spy
Overriding JDO Annotations
JDO/DataNucleus builds its own persistence metamodel by reading both annotations on the class and also by searching for metadata in XML files. The metadata in the XML files takes precedence over the annotations, and so can be used to override metadata that is "hard-coded" in annotations.
In fact, JDO/DataNucleus provides two different XML files that have slightly different purposes and capabilities:
-
first, a
.jdofile can be provided which - if found - completely replaces the annotations.The idea here is simply to use XML as the means by which metadata is specified.
-
second, an
.ormfile can be provided which - if found - provides individual overrides for a particular database vendor.The idea here is to accommodate for subtle differences in support for SQL between vendors. A good example is the default schema for a table:
dbofor SQL Server,publicfor HSQLDB,sysfor Oracle, and so on.
If you want to use the first approach (the .jdo file), you’ll find that you can download the effective XML representation of domain entities using the downloadJdoMetadata() mixin action available in prototyping mode.
This then needs to be renamed and placed in the appropriate location on the classpath; see the DataNucleus documentation for details.
However, using this first approach does create a maintenance effort; if the domain entity’s class structure changes over time, then the XML metadata file will need to be updated.
The second approach (using an .orm file) is therefore often more useful than the first, because the metadata provided overrides rather than replaces the annotations (and annotations not overridden continue to be honoured).
A typical use case is to change the database schema for an entity.
For example, various extension modules use schemas for each entity.
For example, the AuditEntry entity in the audit trail security module is annotated as:
@javax.jdo.annotations.PersistenceCapable(
identityType=IdentityType.DATASTORE,
schema = "causewayAddonsAudit",
table="AuditEntry")
public class AuditEntry {
...
}This will map the AuditEntry class to a table "CausewayAddonsAudit"."AuditEntry"; that is using a custom schema to own the object.
Suppose though that for whatever reason we didn’t want to use a custom schema but would rather use the default. Also suppose we are using SQL Server as our target database.
We can override the above annotation using a AuditEntry-sqlserver.orm file, placed in the same package as the AuditEntry entity.
For example:
<?xml version="1.0" encoding="UTF-8" ?>
<orm xmlns="http://xmlns.jcp.org/xml/ns/jdo/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/jdo/orm
http://xmlns.jcp.org/xml/ns/jdo/orm_3_0.xsd">
<package name="org.causewayaddons.module.audit.dom">
<class name="AuditEntry"
schema="causewayaudit"
table="AuditEntry">
</class>
</package>
</orm>It’s also necessary to tell JDO/DataNucleus about which vendor is being used (sqlserver in the example above).
This is done using the pass-thru datanucleus.Mapping configuration property:
datanucleus.Mapping=sqlserverSubtype not fully populated
Taken from this thread on the Apache Causeway users mailing list…
If it seems that Apache Causeway (or rather DataNucleus) isn’t fully populating domain entities (ie leaving some properties as null), then check that your actions are not accessing the fields directly.
Use getters instead.
|
Properties of domain entities should always be accessed using getters. The only code that should access to fields should be the getters themselves. |
Why so? Because DataNucleus will potentially lazy load some properties, but to do this it needs to know that the field is being requested. This is the purpose of the enhancement phase: the bytecode of the original getter method is actually wrapped in code that does the lazy loading checking. But hitting the field directly means that the lazy loading code does not run.
This error can be subtle: sometimes "incorrect" code that accesses the fields will seem to work. But that will be because the field has been populated already, for whatever reason.
One case where you will find the issue highlighted is for subtype tables that have been mapped using an inheritance strategy of NEW_TABLE, eg:
@javax.jdo.annotations.PersistenceCapable
@javax.jdo.annotations.Inheritance(strategy = InheritanceStrategy.NEW_TABLE)
public class SupertypeEntity {
...
}and then:
@javax.jdo.annotations.PersistenceCapable
@javax.jdo.annotations.Inheritance(strategy = InheritanceStrategy.NEW_TABLE)
public class SubtypeEntity extends SupertypeEntity {
...
}This will generate two tables in the database, with the primary key of the supertype table propagated as a foreign key (also primary key) of the subtype table (sometimes called "table per type" strategy). This means that DataNucleus might retrieve data from only the supertype table, and the lazily load the subtype fields only as required. This is preferable to doing a left outer join from the super- to the subtype tables to retrieve data that might not be needed.
On the other hand, if the SUPERCLASS_TABLE strategy (aka "table per hierarchy" or roll-up) or the SUBCLASS_TABLE strategy (roll-down) was used, then the problem is less likely to occur because DataNucleus would obtain all the data for any given instance from a single table.
Final note: references to other objects (either scalar references or in collections) in particular require that getters rather than fields to be used to obtain them: it’s hopefully obvious that DataNucleus (like all ORMs) should not and will not resolve such references (otherwise, where to stop… and the whole database would be loaded into memory).
In summary, there’s just one rule: always use the getters, never the fields.
Diagnosing n+1 Issues
(As of DN 4.1) set a break point in FetchRequest#execute(…):
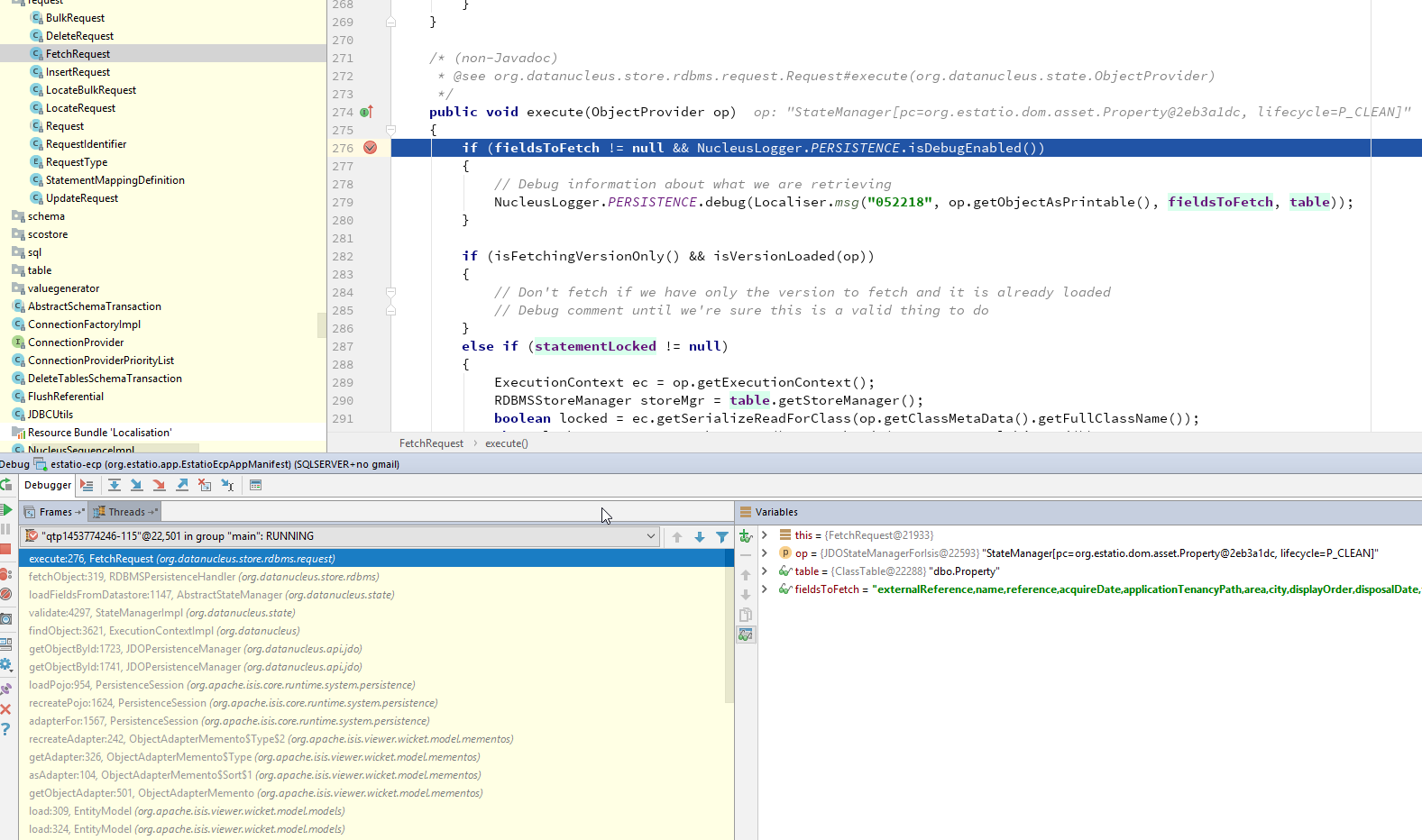
The "Variables" pane will tell you which field(s) are being loaded, and the stack trace should help explain why the field is required.
For example, it may be that an object is being loaded in a table and the initial query did not eagerly load that field. In such a case, consider using fetch groups in the initial repository query to bring the required data into memory with just one SQL call. See this hint/tip for further details.
Typesafe Queries and Fetch-groups
Fetch groups provide a means to hint to DataNucleus that it should perform a SQL join when querying. A common use case is to avoid the n+1 issue.
(So far as I could ascertain) it isn’t possible to specify fetch group hints using JDOQL, but it is possible to specify them using the programmatic API or using typesafe queries.
For example, here’s a JDOQL query:
@Query(
name = "findCompletedOrLaterWithItemsByReportedDate", language = "JDOQL",
value = "SELECT "
+ "FROM com.mycompany.invoice.IncomingInvoice "
+ "WHERE items.contains(ii) "
+ " && (ii.reportedDate == :reportedDate) "
+ " && (approvalState != 'NEW' && approvalState != 'DISCARDED') "
+ "VARIABLES com.mycompany.invoice.IncomingInvoiceItem ii "
),
public class IncomingInvoice ... { /* ... */ }which normally would be used from a repository:
public List<IncomingInvoice> findCompletedOrLaterWithItemsByReportedDate(
final LocalDate reportedDate) {
return repositoryService.allMatches(
Query.named(IncomingInvoice.class,
"findCompletedOrLaterWithItemsByReportedDate")
.withParameter("reportedDate", reportedDate));
}This can be re-written as a type-safe query as follows:
public List<IncomingInvoice> findCompletedOrLaterWithItemsByReportedDate(final LocalDate reportedDate) {
final QIncomingInvoice ii = QIncomingInvoice.candidate();
final QIncomingInvoiceItem iii = QIncomingInvoiceItem.variable("iii");
final TypesafeQuery<IncomingInvoice> q =
causewayJdoSupport.newTypesafeQuery(IncomingInvoice.class);
q.filter(
ii.items.contains(iii)
.and(iii.reportedDate.eq(reportedDate))
.and(ii.approvalState.ne(IncomingInvoiceApprovalState.NEW))
.and(ii.approvalState.ne(IncomingInvoiceApprovalState.DISCARDED)));
final List<IncomingInvoice> incomingInvoices = Lists.newArrayList(q.executeList());
q.closeAll();
return incomingInvoices;
}Now the IncomingInvoice has four fields that require eager loading.
This can be specified by defining a named fetch group:
@FetchGroup(
name="seller_buyer_property_bankAccount",
members={
@Persistent(name="seller"),
@Persistent(name="buyer"),
@Persistent(name="property"),
@Persistent(name="bankAccount")
})
public class IncomingInvoice ... { /* ... */ }This fetch group can then be used in the query using q.getFetchPlan().addGroup(…).
Putting this all together, we get:
public List<IncomingInvoice> findCompletedOrLaterWithItemsByReportedDate(final LocalDate reportedDate) {
final QIncomingInvoice ii = QIncomingInvoice.candidate();
final QIncomingInvoiceItem iii = QIncomingInvoiceItem.variable("iii");
final TypesafeQuery<IncomingInvoice> q =
causewayJdoSupport.newTypesafeQuery(IncomingInvoice.class);
q.getFetchPlan().addGroup("seller_buyer_property_bankAccount"); (1)
q.filter(
ii.items.contains(iii)
.and(iii.reportedDate.eq(reportedDate))
.and(ii.approvalState.ne(IncomingInvoiceApprovalState.NEW))
.and(ii.approvalState.ne(IncomingInvoiceApprovalState.DISCARDED)));
final List<IncomingInvoice> incomingInvoices = Lists.newArrayList(q.executeList());
q.closeAll();
return incomingInvoices;
}| 1 | specify the fetch group to use. |
JDOQL and Timestamps
Beware of entities with a property called "timestamp": you run the risk of "timestamp" being treated as a keyword in certain contexts, probably not as you intended.
By way of example, the Command Log module has an entity called CommandJdo.
This has a property called "timestamp", of type java.sql.Timestamp.
This defines a query using JDOQL:
SELECT
FROM org.causewayaddons.module.command.dom.CommandJdo
WHERE executeIn == 'FOREGROUND'
&& timestamp > :timestamp
&& startedAt != null
&& completedAt != null
ORDER BY timestamp ASCThis is declared using a JDO @Query; no errors are thrown at any stage.
However, running this query against SQL Server 2016 produced a different result first time it was run compared to subsequent times.
Running SQL Profiler showed the underlying SQL as:
exec sp_prepexec @p1 output,N'@P0 datetime2',
N'SELECT ''org.causewayaddons.module.command.dom.CommandJdo'' AS NUCLEUS_TYPE,
A0.arguments,
...,
A0.target,
A0."timestamp",
A0.transactionId,
A0."user",
''2018-01-24 17:29:18.3'' AS NUCORDER0 (1)
FROM causewaycommand.Command A0
WHERE A0.executeIn = ''FOREGROUND''
AND A0."timestamp" > @P0
AND A0.startedAt IS NOT NULL
AND A0.completedAt IS NOT NULL
ORDER BY NUCORDER0
OFFSET 0 ROWS FETCH NEXT 2 ROWS ONLY ', (2)
'2018-01-24 17:29:18.3000000' (3)| 1 | discussed below … this is the issue |
| 2 | because the query is submitted with max rows programmatically set to 2. |
| 3 | argument for @P0 (the timestamp parametr) |
To unpick this, the key issue is the NUCORDER0 column, which is then used in the ORDER BY.
However, because this is a literal value, the effect is no defined ordering.
The problem therefore is that in the JDOQL the "ORDER BY timestamp ASC", the "timestamp" is being evaluated as the current time - a built-in function.
My fix was to change the JDOQL to be:
SELECT
FROM org.causewayaddons.module.command.dom.CommandJdo
WHERE executeIn == 'FOREGROUND'
&& timestamp > :timestamp
&& startedAt != null
&& completedAt != null
ORDER BY this.timestamp ASC (1)| 1 | Use "this." to qualify the timestamp |
It wasn’t necessary to qualify the other occurances of "timestamp" (though it would be no harm to do so, either).